Kedro integration guide#
Kedro is a popular open source project that helps standardize ML workflows. The Kedro–Neptune plugin adds a powerful and flexible UI on top of your Kedro pipelines:
- Browse, filter, and sort your model training runs.
- Compare nodes and pipelines on metrics and visual node outputs.
- Display pipeline metadata, including:
- Learning curves for metrics, plots, and images.
- Rich media, such as video and audio.
- Interactive visualizations from Plotly, Altair, or Bokeh.
The Kedro-Neptune plugin supports distributed pipeline execution. It works in Kedro setups that use orchestrators, such as Airflow or Kubeflow.
See Kedro example in Neptune Code examples
Before you start#
- Sign up at neptune.ai/register.
- Create a project for storing your metadata.
- Have Kedro installed.
Installing the plugin#
To use your preinstalled version of Neptune together with the integration:
To install both Neptune and the integration:
Passing your Neptune credentials
Once you've registered and created a project, set your Neptune API token and full project name to the NEPTUNE_API_TOKEN and NEPTUNE_PROJECT environment variables, respectively.
To find your API token: In the bottom-left corner of the Neptune app, expand the user menu and select Get my API token.
Your full project name has the form workspace-name/project-name. You can copy it from the project settings: Click the menu in the top-right → Edit project details.
On Windows, navigate to Settings → Edit the system environment variables, or enter the following in Command Prompt: setx SOME_NEPTUNE_VARIABLE 'some-value'
While it's not recommended especially for the API token, you can also pass your credentials in the code when initializing Neptune.
run = neptune.init_run(
project="ml-team/classification", # your full project name here
api_token="h0dHBzOi8aHR0cHM6Lkc78ghs74kl0jvYh...3Kb8", # your API token here
)
For more help, see Set Neptune credentials.
Setup and logging example#
-
Create a Kedro project from the
spaceflightsstarter.-
To create a Kedro starter project, enter the following on the command line or in a terminal app:
For detailed instructions, see the Kedro docs .
-
Follow the instructions and choose a name for your Kedro project.
- Navigate to your new Kedro project directory.
Example structurespaceflights-pandas ├── conf ├── base ├── catalog.yml ├── neptune.yml ... ├── local ├── credentials_neptune.yml ... ├── data ├── docs ├── notebooks ├── src └── spaceflights-pandas ├── pipelines ├── data_processing ├── data_science ├── nodes.py ├── pipeline.py ... ... ├── settings.py ... ...In this example, we'll use
catalog.yml,neptune.yml,credentials_neptune.yml,nodes.py,pipeline.py, andsettings.py. -
-
Initialize the Kedro-Neptune plugin.
-
In your Kedro project directory, enter the
kedro neptune initcommand:Tip
You can log dependencies with the
dependenciesparameter. Either pass the path to your requirements file, or passinferto have Neptune log the currently installed dependencies in your environment. -
You are prompted for your API token.
- If you've saved it to the
NEPTUNE_API_TOKENenvironment variable (recommended), just press Enter without typing anything. - If you've set your Neptune API token to a different environment variable, enter that instead. For example,
MY_SPECIAL_NEPTUNE_TOKEN_VARIABLE. - You can also copy and enter your Neptune API token directly (not recommended).
- If you've saved it to the
-
You are prompted for a Neptune project name.
- If you've saved it to the
NEPTUNE_PROJECTenvironment variable (recommended), just press Enter without typing anything. - If you've set your Neptune API token to a different environment variable, enter that instead. For example,
MY_SPECIAL_NEPTUNE_PROJECT_VARIABLE. - You can also enter your Neptune project name in the form
workspace-name/project-name. If you're not sure about the full name, go to the project settings in the Neptune app.
- If you've saved it to the
If everything was set up correctly...
You should see the following message:
-
-
Add the config patterns needed to load the Neptune config to your project's
CONFIG_LOADER_ARGSinspaceflights-pandas\src\spaceflights\settings.py: -
Add Neptune logging to a Kedro node.
-
Open a pipeline node:
spaceflights-pandas\src\spaceflights\pipelines\data_science\nodes.py -
In the
nodes.pyfile, import Neptune: -
Add the
neptune_runargument of typeneptune.handler.Handlerto theevaluate_model()function:nodes.pydef evaluate_model( regressor: LinearRegression, X_test: pd.DataFrame, y_test: pd.Series, neptune_run: neptune.handler.Handler, ): ...Tip
You can treat
neptune_runlike a normal Neptune run and log metadata to it as you normally would.You must use the special string
neptune_runas the run handler in Kedro pipelines. -
Log metrics like score to
neptune_run:nodes.pydef evaluate_model( regressor: LinearRegression, X_test: pd.DataFrame, y_test: pd.Series, neptune_run: neptune.handler.Handler, ): y_pred = regressor.predict(X_test) score = r2_score(y_test, y_pred) logger = logging.getLogger(__name__) logger.info("Model has a coefficient R^2 of %.3f on test data.", score) neptune_run["nodes/evaluate_model_node/score"] = scoreThe
nodes/evaluate_model_node/scorestructure is an example. You can define your own. -
Log images:
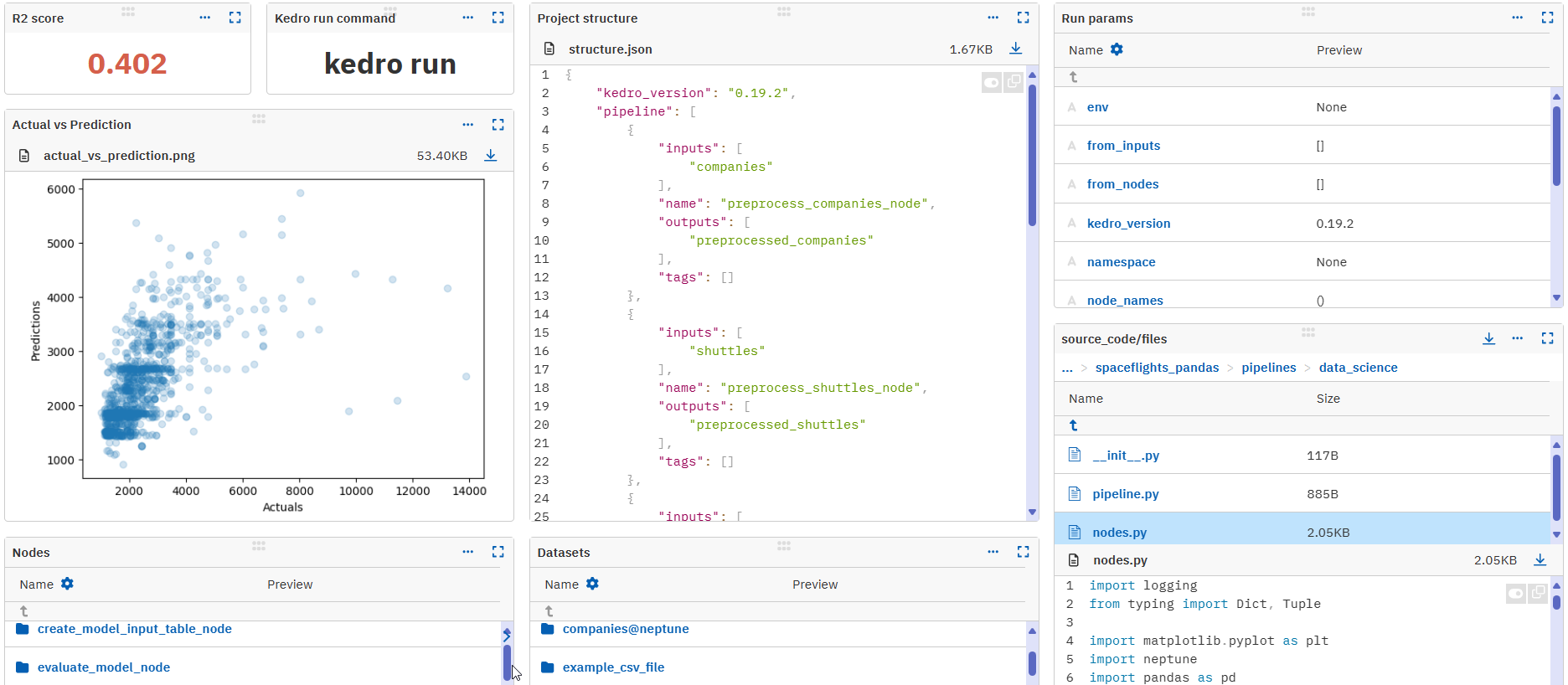
nodes.pyimport matplotlib.pyplot as plt ... def evaluate_model( regressor: LinearRegression, X_test: pd.DataFrame, y_test: pd.Series, neptune_run: neptune.handler.Handler, ): y_pred = regressor.predict(X_test) score = r2_score(y_test, y_pred) logger = logging.getLogger(__name__) logger.info("Model has a coefficient R^2 of %.3f on test data.", score) fig = plt.figure() plt.scatter(y_test.values, y_pred, alpha=0.2) plt.xlabel("Actuals") plt.ylabel("Predictions") neptune_run["nodes/evaluate_model_node/score"] = score neptune_run["nodes/evaluate_model_node/actual_vs_prediction"].upload(fig)You can also log other other types of metadata in a structure of your own choosing. For details, see What you can log and display.
-
-
Add the Neptune run handler to the Kedro pipeline.
-
Go to a pipeline definition:
spaceflights-pandas\src\spaceflights\pipelines\data_science\pipeline.py -
Add the
neptune_runhandler as an input to theevaluate_modelnode:
-
-
On the command line, execute the Kedro project:
To open the Neptune run in the app, click the Neptune link that appears in the console.
Example link: https://app.neptune.ai/o/showcase/org/kedro/e/KED-1
Now you can explore the results in the Neptune app.
- In the All metadata section of the run view, click the kedro namespace to view the metadata from the Kedro pipelines.
- kedro/catalog/datasets: dataset metadata
- kedro/catalog/parameters: pipeline and node parameters
- kedro/nodes: details of all the nodes in the project
- kedro/nodes/evaluate_model_node/score: the \(R^2\) value we logged
- kedro/run_params: execution parameters
- kedro/structure: JSON structure of the kedro pipeline
More options#
Basic logging configuration#
You can configure where and how Kedro pipeline metadata is logged by editing the conf/base/neptune.yml file.
neptune:
#GLOBAL CONFIG
project: $NEPTUNE_PROJECT
base_namespace: kedro
dependencies:
enabled: true
#LOGGING
upload_source_files:
- '**/*.py'
- conf/base/*.yml
where
projectis the name of the Neptune project where metadata is stored. If you haven't set the$NEPTUNE_PROJECTenvironment variable, you can replace it with the full name of your Neptune project (workspace-name/project-name).base_namespaceis the base namespace (folder) where your metadata will be logged. The default iskedro.dependenciesdetermines if your python environment requirements will be logged. You can pass the path to your requirements file, or passinferto have Neptune log the currently installed dependencies in your environment. Dependencies won't be logged by default.-
enableddetermines if Neptune logging is enabled. The default istrue.Disabling Neptune
To turn off Neptune logging in a Kedro project, see Disabling Neptune.
-
upload_source_filesis used to list files you want to automatically upload to Neptune when a run is created.
Configuring Neptune API token#
You can configure how the Kedro-Neptune plugin will look for your Neptune API token in the conf/local/credentials_neptune.yml file.
You can:
-
leave it empty, in which case Neptune will look for your token in the
$NEPTUNE_API_TOKENenvironment variable.Important
There must be a dollar sign (
$) before the variable name. -
pass a different environment variable, such as
$MY_SPECIAL_NEPTUNE_API_TOKEN_VARIABLE. - pass your token as a string, such as
eyJhcGlfYWRk123cmVqgpije5cyI6Imh0dHBzOi8v(not recommended).
How do I find my API token?
In the bottom-left corner of the Neptune app, open the user menu and select Get your API token.
You can copy your token from the dialog that opens. It's very long – make sure to copy and paste it in full!
Logging files and datasets#
You can log files to Neptune with a special Kedro Dataset called kedro_neptune.NeptuneFileDataset.
To log files, add the dataset to your conf/base/catalog.yml file:
example_csv_file:
type: kedro_neptune.NeptuneFileDataset
filepath: data/01_raw/companies.csv
where filepath is the path to the file you'd like to log. (Do not change the type value.)
You can find and preview all the logged NeptuneFileDatasets in the kedro/catalog/files namespace of the run.
Logging an existing Kedro Dataset#
If you already have a Kedro Dataset that you would log under the same name to Neptune, add @neptune to the Dataset name:
companies:
type: pandas.CSVDataset
filepath: data/01_raw/companies.csv
companies@neptune:
type: kedro_neptune.NeptuneFileDataset
filepath: data/01_raw/companies.csv
Note
Rather than uploading the whole training dataset to Neptune, upload a small, informative part that you would like to display later.
To upload files to Neptune, you can also do it directly through Neptune API with the upload() and upload_files() methods:
You can also track the dataset file as an artifact with the track_files() method. This can be useful particularly if the file is large, or you are mainly interested in tracking its version:
Related
- Learn more about tracking artifacts.
- For other types of metadata you can track, see What you can log and display.
- Instead of user accounts, you can set up service accounts to automate your workflow.
Disabling Neptune#
To disable Neptune in your Kedro project:
-
Set the
enabledflag tofalsein theneptune.ymlfile: -
Wrap manual logging code within Kedro nodes inside a condition to log only when
neptune_runexists:nodes.pydef evaluate_model( regressor: LinearRegression, X_test: pd.DataFrame, y_test: pd.Series, neptune_run: neptune.handler.Handler, ): y_pred = regressor.predict(X_test) score = r2_score(y_test, y_pred) logger = logging.getLogger(__name__) logger.info("Model has a coefficient R^2 of %.3f on test data.", score) if neptune_run: neptune_run["nodes/evaluate_model_node/score"] = score neptune_run["nodes/evaluate_model_node/actual_vs_prediction"].upload(fig)
Related
- kedro-neptune repo on GitHub
- Kedro website