![]()
Restarting a run from a checkpoint#
When running ML experiments, it is useful to save progress as a checkpoint to be able to resume the experiment from that point later. This ensures that no progress is lost in scenarios such as server disruptions or failures.
In this guide, you'll learn how to resume your experiment from a previously saved checkpoint.
See example in Neptune See full code example on GitHub
Before you start#
Assumptions
You have Neptune installed and your Neptune credentials are saved as environment variables.
For details, see Install Neptune.
Saving checkpoints while logging#
As part of your epoch loop, add a script that uploads the checkpoint to the Neptune run. Depending on the checkpoint saving frequency, this would store a checkpoint for each epoch under the path checkpoints/epoch_<epoch_number> inside the run.
You can then fetch any logged checkpoint from this namespace and resume the training from there.
The below sample illustrates the idea.
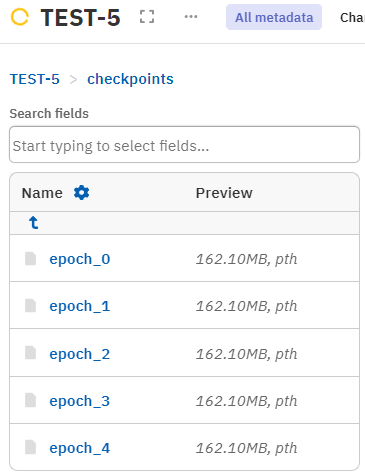
Fetching an epoch and loading the checkpoint#
Reinitializing the Neptune run#
If your Neptune run is no longer active, you need to resume it in your code. For this, you just need the ID of the run. It consists of the project key and a counter. For example TFKERAS-7.
You can grab the ID manually from the Runs table. It's displayed in the leftmost column.
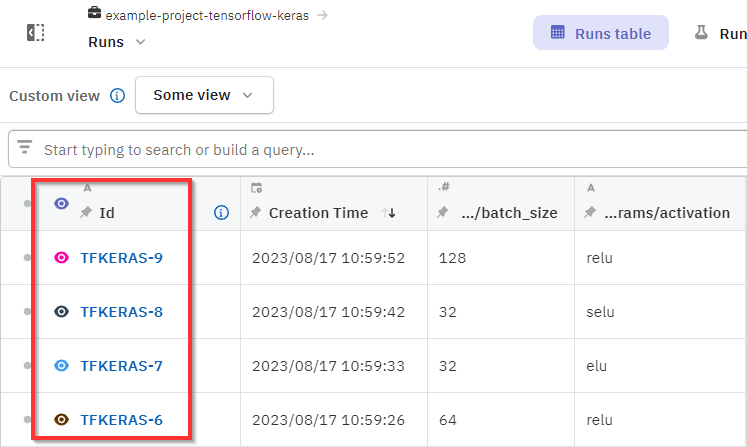
In your code:
Fetching the ID via API#
You can also obtain the ID programmatically. Connect to your project with init_project() and fetch the last failed run:
with neptune.init_project(mode="read-only") as project:
runs_table_df = project.fetch_runs_table(state="inactive").to_pandas()
run_id = runs_table_df[runs_table_df["sys/failed"] == True]["sys/id"].values[0]
Note
If your run status is not actually "Failed", you can leave out the "sys/failed"] == True condition.
Learn more about the status: API reference → sys/failed
Using the ID obtained in the previous step, we can reopen the existing run.
Loading the checkpoint#
You can now enter the epoch number to resume the training from.
epoch = 3
checkpoint_name = f"epoch_{epoch}"
ext = run["checkpoints"][checkpoint_name].fetch_extension()
Use the download() method to obtain the checkpoint from the Neptune run, then load it up.
run["checkpoints"][checkpoint_name].download()
run.wait()
checkpoint = torch_load(f"{checkpoint_name}.{ext}")
Fetching last epoch automatically#
The following script demonstrates how you could fetch the epoch of the last logged checkpoint automatically.
def load_checkpoint(run: neptune.Run, epoch: int):
checkpoint_name = f"epoch_{epoch}"
ext = run["checkpoints"][checkpoint_name].fetch_extension()
run["checkpoints"][checkpoint_name].download() # Download the checkpoint
run.wait()
checkpoint = torch_load(f"{checkpoint_name}.{ext}") # Load the checkpoint
return checkpoint
checkpoints = run.get_structure()["checkpoints"]
The below code accesses the logged epoch numbers and finds the last one.
epochs = [
int(checkpoint.split("_")[-1]) for checkpoint in checkpoints
]
epochs.sort()
epoch = epochs[-1]
Finally, we can load the checkpoint using the obtained epoch number.
Loading the model and optimizer state#
Next, we use the loaded checkpoint to set up the model and optimizer.
model.load_state_dict(checkpoint["model_state_dict"])
optimizer.load_state_dict(checkpoint["optimizer_state_dict"])
Resuming the training#
We're ready to resume the training using the checkpoint obtained from the initial run.
def train(
run: neptune.Run,
model: nn.Module,
dataloader: DataLoader,
criterion: nn.Module,
optimizer: optim.Optimizer,
parameters: Dict[str, Any],
start_epoch: int = 0,
):
for epoch in range(start_epoch, parameters["num_epochs"]):
for i, (x, y) in enumerate(dataloader, 0):
x, y = x.to(parameters["device"]), y.to(parameters["device"])
optimizer.zero_grad()
outputs = model(x)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, y)
acc = (torch.sum(preds == y.data)) / len(x)
run["metrics"]["batch/loss"].append(loss.item())
run["metrics"]["batch/acc"].append(acc.item())
loss.backward()
optimizer.step()
if epoch % parameters["ckpt_frequency"] == 0:
save_checkpoint(run, model, optimizer, epoch, loss)
train(
run,
model,
trainloader,
criterion,
optimizer,
parameters,
start_epoch=checkpoint["epoch"],
)
Stop the run when done
Once you are done logging, you should stop the connection to the Neptune run. When logging from a Jupyter notebook or other interactive environments, you need to do this manually:
If you're running a script, the connection is stopped automatically when the script finishes executing. In interactive sessions, however, the connection to Neptune is only stopped when the kernel stops.