Introduction to neptune.ai#
Neptune functions as a combined database and dashboard.
You and your teammates can run model training on a laptop, cloud environment, or computation cluster and log all model metadata to a central workspace.
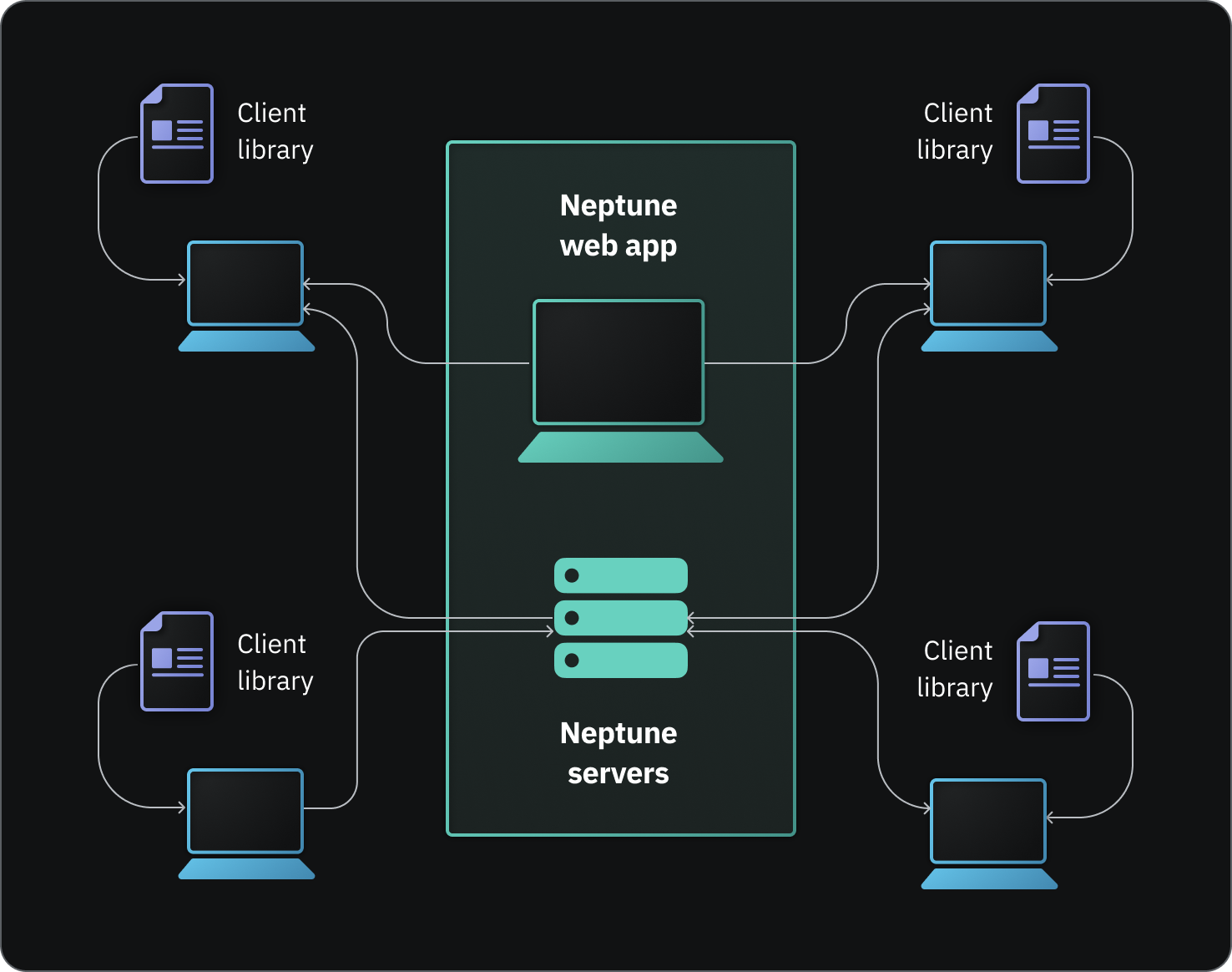
How does it work?#
Neptune consists of:
- neptune – Python client library (API) for logging and querying model-building metadata.
- app.neptune.ai – web app for visualization, comparison, monitoring, and collaboration.

You can have a workspace for each team or organization that you're working with. Within a workspace, you can create a project for each ML task you're solving.
Examples of ML metadata that Neptune can track
Experiment and model training metadata:
- Metrics, hyperparameters, learning curves
- Training code and configuration files
- Predictions (images, tables)
- Diagnostic charts (Confusion matrices, ROC curves)
- Console logs and hardware usage
- Environment information (dependencies, Git)
Artifact metadata:
- Paths to the dataset or model (Amazon S3 bucket, filesystem)
- Dataset hash
- Dataset or prediction preview (head of the table, snapshot of the image folder)
- Feature column names (for tabular data)
- When and by whom an artifact was created or modified
- Size and description
Trained model metadata:
- Model binaries or location of your model assets
- Dataset versions
- Links to recorded model-training runs and experiments
- Who trained the model
- Model descriptions and notes
- Links to observability dashboards (like Grafana)
For a complete reference of what you can track, see What you can log and display.
Log and query access is controlled with API tokens, which can be associated either with regular users or (non-human) service accounts.
Enterprise plans include project-level access control, which means you can manage members' access to each project.1
Flexible API#
The Neptune API is an open-source suite of libraries that help you:
- Log and fetch experimentation metadata.
- Manage users, workspaces, and usage.
- Track model metadata and manage the model lifecycle.
A Neptune run is the basic unit of a model-training experiment. Typically, you create a run every time you execute a script that does model training, retraining, or inference.
It's up to you to define what to log for each run and in what kind of structure.
import neptune
from sklearn.datasets import load_wine
...
run = neptune.init_run()
data = load_wine()
X_train, X_test, y_train, y_test = train_test_split(...)
PARAMS = {"n_estimators": 10, "max_depth": 3, ...}
run["parameters"] = PARAMS
...
test_f1 = f1_score(y_test, y_test_pred.argmax(axis=1), average="macro")
run["test/f1"] = test_f1

Integrations#
Neptune integrates with many frameworks in the ML ecosystem.
Instead of writing the logging code yourself, you can typically create a Neptune logger or callback that you pass along in your code:2
import neptune
from neptune.integrations.tensorflow_keras import NeptuneCallback
neptune_run = neptune.init_run()
model.fit(
...
callbacks=[NeptuneCallback(run=neptune_run)],
)
The above code takes care of logging metadata that is typically generated during Keras training runs.
For more, see Integrations.
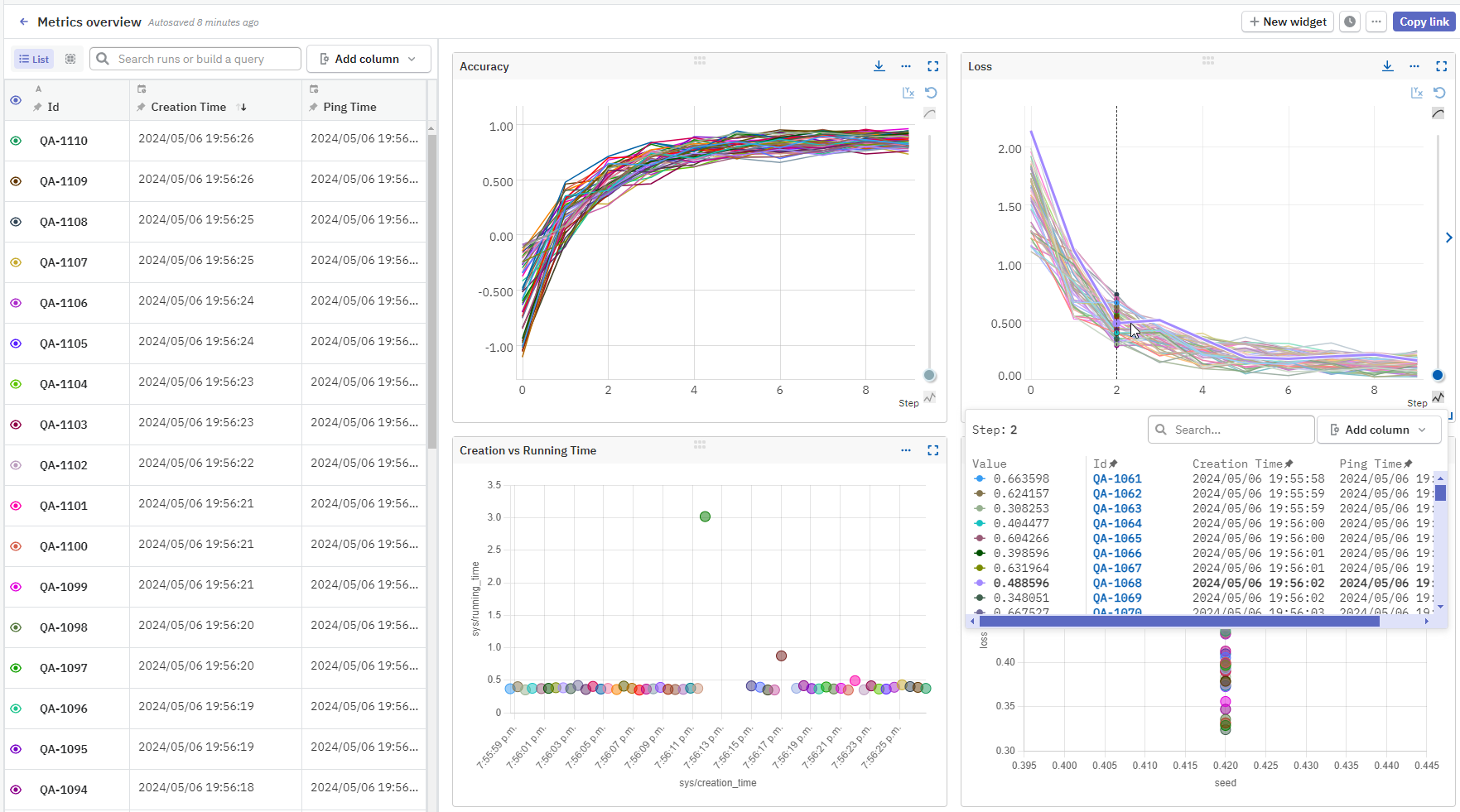
Web app#
The web application is your UI to the logged metadata. It's where you can:
- Have the data visualized, sorted, and organized.
- Watch the training live and stop runs remotely.
- Browse tracebacks, system metrics, and source code.
- Download visualizations and logged metadata.

Each tracked run appears in the Experiments table of your project, where you can display and arrange the metadata to your liking.
The customizable sections are shared among all project members:
- Views – save different views of the experiments table, to quickly find best-performing runs or all experiments for a particular model type.
- Dashboards – display what you think is important in a single view, such as metrics, predictions, configurations, logs, or data samples.
- Reports – export dashboards along with visible runs, for shareable analyses of particular experiments.
Neptune has persistent URLs, which means that whenever you change something in the Neptune app, the URL updates to reflect the changes. When you share this URL with other people, it takes them to the very same view of the Neptune app that you're seeing.
What do I need in order to use Neptune?#
To use the SaaS (online) version of Neptune, you need an internet connection from your system.
To set up logging and perform queries through the client library (API):
- You or your team should have a working knowledge of Python.
- You do not need extensive command-line experience, but you should know:
- How to set environment variables in your system, to store Neptune credentials more securely.
- How to open and enter commands through a terminal, so you can use the Neptune command-line interface tool to synchronize local data with Neptune servers.
You can do the following without coding or technical expertise:
- Explore, sort, and organize the logged metadata in the web application.
- Edit details such as names, descriptions, and tags.
- Manage workspaces, projects, members, and permissions.
- Create and manage service accounts.
- Trash and delete data.
Self-hosting#
You can also install Neptune on your own infrastructure (on-premises) or in a private cloud.
For details, see Self-hosted Neptune.
Learn more#
Need more information? Check out the following: