Tracking and visualizing cross validation results#
![]()
When training models with cross validation, you can use Neptune namespaces (folders) to organize, visualize and compare models. You can also use namespaces to present cross-validation results, for example, when experimenting with k-fold validation or train/validation/test splits.
In this guide, you'll learn how to analyze your results more easily by organizing your run to track cross-validation metadata.
See example in Neptune Code examples
Before you start#
- Sign up at neptune.ai/register.
- Create a project for storing your metadata.
-
Install Neptune:
Installing through Anaconda Navigator
To find neptune, you may need to update your channels and index.
- In the Navigator, select Environments.
- In the package view, click Channels.
- Click Add..., enter
conda-forge, and click Update channels. - In the package view, click Update index... and wait until the update is complete. This can take several minutes.
- You should now be able to search for neptune.
Note: The displayed version may be outdated. The latest version of the package will be installed.
Note: On Bioconda, there is a "neptune" package available which is not the neptune.ai client library. Make sure to specify the "conda-forge" channel when installing neptune.ai.
Passing your Neptune credentials
Once you've registered and created a project, set your Neptune API token and full project name to the
NEPTUNE_API_TOKENandNEPTUNE_PROJECTenvironment variables, respectively.To find your API token: In the bottom-left corner of the Neptune app, expand the user menu and select Get my API token.
Your full project name has the form
workspace-name/project-name. You can copy it from the project settings: Click the menu in the top-right → Details & privacy.On Windows, navigate to Settings → Edit the system environment variables, or enter the following in Command Prompt:
setx SOME_NEPTUNE_VARIABLE 'some-value'
While it's not recommended especially for the API token, you can also pass your credentials in the code when initializing Neptune.
run = neptune.init_run( project="ml-team/classification", # your full project name here api_token="h0dHBzOi8aHR0cHM6Lkc78ghs74kl0jvYh...3Kb8", # your API token here )For more help, see Set Neptune credentials.
Integration tip
When using the Neptune integration with for example XGBoost and LightGBM, you get this structure for cross-validation metadata automatically.
Learn more: XGBoost integration guide, LightGBM integration guide
Create a script that tracks cross-validation metadata#
We'll create a model training script where we run k-fold validation and log some parameters and metrics.
To organize the run, we'll create two categories of namespace:
| Namespace name | Description | Metadata inside the namespace |
|---|---|---|
global |
Metadata common to all folds |
|
fold_n |
Metadata specific to each fold |
|
This structure helps you organize metadata from different folds into folders and a global aggregate of all metrics – that is, an accuracy chart of all folds. This makes it easier to navigate, compare, and retrieve metadata from any of the folds, both in the app and through the API.
The highlighted lines show where Neptune logging comes in.
import neptune
from neptune.utils import stringify_unsupported
run = neptune.init_run() # (1)!
parameters = {
"epochs": 1,
"learning_rate": 1e-2,
"batch_size": 10,
"image_size": (3, 32, 32),
"n_classes": 10,
"k_folds": 2,
"checkpoint_name": "checkpoint.pth",
"seed": 42,
}
run["parameters"] = stringify_unsupported(parameters)
splits = KFold(n_splits=parameters["k_folds"], shuffle=True)
for fold, (train_ids, val_ids) in enumerate(splits.split(dataset)):
for epoch in range(parameters["epochs"]):
for i, (x, y) in enumerate(trainloader, 0):
# Log batch loss
run[f"fold_{fold}/training/batch/loss"].append(loss)
# Log batch accuracy
run[f"fold_{fold}/training/batch/acc"].append(acc)
# Log model checkpoint
torch.save(model.state_dict(), f"./{parameters['checkpoint_name']}")
run[f"fold_{fold}/checkpoint"].upload(parameters["checkpoint_name"])
run["global/metrics/train/mean_acc"] = mean(epoch_acc_list)
run["global/metrics/train/mean_loss"] = mean(epoch_loss_list)
-
We recommend saving your API token and project name as environment variables.
If needed, you can pass them as arguments when initializing Neptune:
from statistics import mean
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.model_selection import KFold
from torch.utils.data import DataLoader, SubsetRandomSampler
from tqdm.auto import tqdm, trange
from torchvision import datasets, transforms
from functools import reduce
import neptune
from neptune.utils import stringify_unsupported
# Step 1: Create a Neptune run
run = neptune.init_run() # (1)!
# Step 2: Log config and hyperparameters
parameters = {
"epochs": 1,
"learning_rate": 1e-2,
"batch_size": 10,
"image_size": (3, 32, 32),
"n_classes": 10,
"k_folds": 2,
"checkpoint_name": "checkpoint.pth",
"dataset_size": 1000,
"seed": 42,
}
# Log hyperparameters
run["parameters"] = stringify_unsupported(parameters)
image_size = reduce(lambda x, y: x * y, parameters["image_size"])
# Model
class BaseModel(nn.Module):
def __init__(self, input_sz, hidden_dim, n_classes):
super(BaseModel, self).__init__()
self.main = nn.Sequential(
nn.Linear(input_sz, hidden_dim * 2),
nn.ReLU(),
nn.Linear(hidden_dim * 2, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim // 2),
nn.ReLU(),
nn.Linear(hidden_dim // 2, n_classes),
)
def forward(self, input):
x = input.view(-1, image_size)
return self.main(x)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
run["parameters/device"] = str(device) # Log to run parameters
# Seed
torch.manual_seed(parameters["seed"])
model = BaseModel(
image_size,
image_size,
parameters["n_classes"],
).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=parameters["learning_rate"])
data_tfms = {
"train": transforms.Compose(
[
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
]
)
}
dataset = datasets.FakeData(
size=parameters["dataset_size"],
image_size=parameters["image_size"],
num_classes=parameters["n_classes"],
transform=data_tfms["train"],
)
# Log dataset details
run["dataset/transforms"] = stringify_unsupported(data_tfms)
run["dataset/size"] = parameters["dataset_size"]
# Training loop
splits = KFold(n_splits=parameters["k_folds"], shuffle=True)
epoch_acc_list, epoch_loss_list = [], []
# Step 3: Log losses and metrics per fold
for fold, (train_ids, _) in tqdm(enumerate(splits.split(dataset))):
train_sampler = SubsetRandomSampler(train_ids)
train_loader = DataLoader(
dataset, batch_size=parameters["batch_size"], sampler=train_sampler
)
for _ in trange(parameters["epochs"]):
epoch_acc, epoch_loss = 0, 0.0
for x, y in train_loader:
x, y = x.to(device), y.to(device)
optimizer.zero_grad()
outputs = model.forward(x)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, y)
acc = (torch.sum(preds == y.data)) / len(x)
# Log batch loss and acc
run[f"fold_{fold}/training/batch/loss"].append(loss)
run[f"fold_{fold}/training/batch/acc"].append(acc)
loss.backward()
optimizer.step()
epoch_acc += torch.sum(preds == y.data).item()
epoch_loss += loss.item() * x.size(0)
epoch_acc_list.append((epoch_acc / len(train_loader.sampler)) * 100)
epoch_loss_list.append(epoch_loss / len(train_loader.sampler))
# Log model checkpoint
torch.save(model.state_dict(), f"./{parameters['checkpoint_name']}")
run[f"fold_{fold}/checkpoint"].upload(parameters["checkpoint_name"])
run.sync()
# Log mean of metrics across all folds
run["results/metrics/train/mean_acc"] = mean(epoch_acc_list)
run["results/metrics/train/mean_loss"] = mean(epoch_loss_list)
run.stop()
-
We recommend saving your API token and project name as environment variables.
If needed, you can pass them as arguments when initializing Neptune:
Run the script#
After you execute the Python script or notebook cell, you should see a Neptune link printed to the console output.
Sample output
[neptune] [info ] Neptune initialized. Open in the app: https://app.neptune.ai/workspace/project/e/RUN-1
Follow the link to open the run in Neptune.
If Neptune can't find your project name or API token
As a best practice, you should save your Neptune API token and project name as environment variables:
Alternatively, you can pass the information when using a function that takes api_token and project as arguments:
run = neptune.init_run( # (1)!
api_token="h0dHBzOi8aHR0cHM6Lkc78ghs74kl0jv...Yh3Kb8", # (2)!
project="ml-team/classification", # (3)!
)
- Also works for
init_model(),init_model_version(),init_project(), and integrations that create Neptune runs underneath the hood, such asNeptuneLoggerorNeptuneCallback. - In the bottom-left corner, expand the user menu and select Get my API token.
- You can copy the path from the project details ( → Details & privacy).
If you haven't registered, you can log anonymously to a public project:
Make sure not to publish sensitive data through your code!
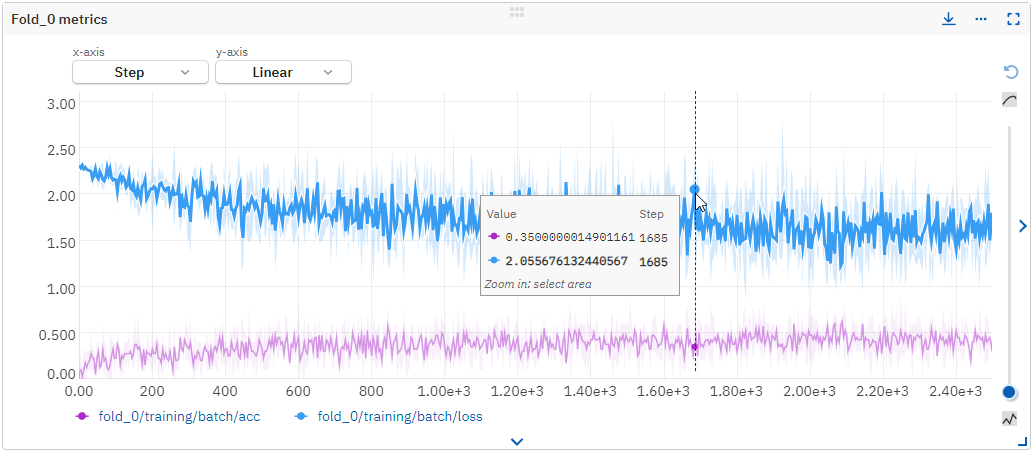
Analyze cross-validation results#
In the All metadata section of each run, you can browse the cross-validation results both per fold and on job level.
- To view global scores, navigate to the "global" namespace.
- To analyze the metrics per fold, navigate through each fold namespace.
See example in Neptune Code examples
You can also create a custom dashboard, where you can combine and overlay the metrics from different namespaces according to your needs.
Related