CatBoost integration guide#
![]()
CatBoost is a high-performance open source library for gradient boosting on decision trees. This guide will show you how to:
- Upload experiment datasets
- Upload CatBoost model parameters and attributes
- Upload training results to Neptune
See example in Neptune Code examples
Before you start#
- Sign up at neptune.ai/register.
-
Create a project for storing your metadata.
-
Have Neptune and CatBoost installed.
To follow the example, you will also need to install ipython, ipywidgets, and scikit-learn.
Passing your Neptune credentials
Once you've registered and created a project, set your Neptune API token and full project name to the NEPTUNE_API_TOKEN and NEPTUNE_PROJECT environment variables, respectively.
To find your API token: In the bottom-left corner of the Neptune app, expand the user menu and select Get my API token.
Your full project name has the form workspace-name/project-name. You can copy it from the project settings: Click the
menu in the top-right →
Details & privacy.
On Windows, navigate to Settings → Edit the system environment variables, or enter the following in Command Prompt: setx SOME_NEPTUNE_VARIABLE 'some-value'
While it's not recommended especially for the API token, you can also pass your credentials in the code when initializing Neptune.
run = neptune.init_run(
project="ml-team/classification", # your full project name here
api_token="h0dHBzOi8aHR0cHM6Lkc78ghs74kl0jvYh...3Kb8", # your API token here
)
For more help, see Set Neptune credentials.
Start a run#
-
If you haven't set up your credentials, you can log anonymously:
We'll use the run object we just created to log metadata. You'll see the metadata appear in the app.
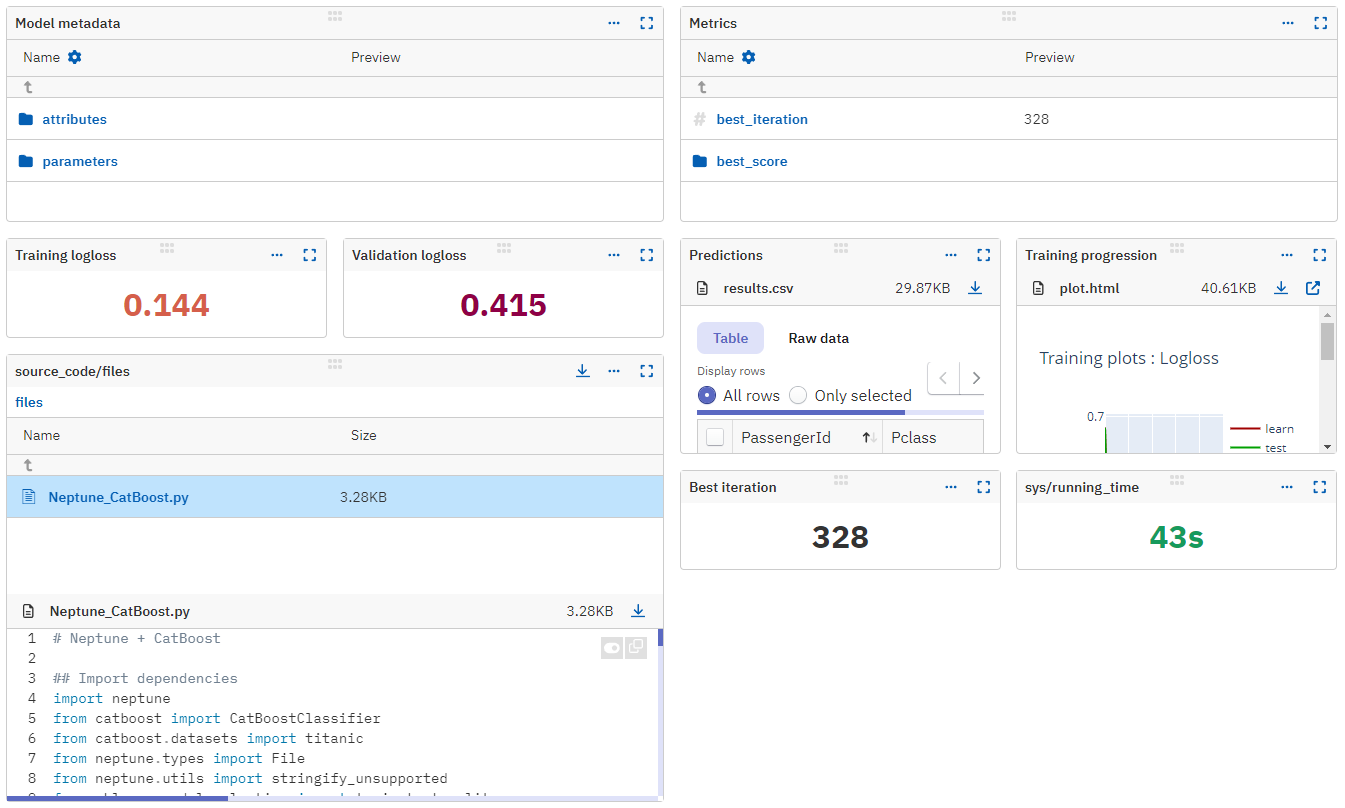
Log training metadata#
from catboost import CatBoostClassifier
model = CatBoostClassifier()
plot_file = "training_plot.html"
model.fit(
X=X_train,
y=y_train,
eval_set=(X_eval, y_eval),
cat_features=cat_features,
text_features=text_features,
plot=True,
plot_file=plot_file,
use_best_model=True,
)
The training plot can be uploaded as an interactive plot file:
You can log the training metrics to Neptune using the = operator.
from neptune.utils import stringify_unsupported
run["training/best_score"] = stringify_unsupported(model.get_best_score())
run["training/best_iteration"] = stringify_unsupported(model.get_best_iteration())
You can save and upload your predictions to Neptune as a CSV file using the to_csv() method to view them in an interactive table.
Related
For more information on logging and visualizing DataFrames, see How to use Neptune with pandas.
Upload model metadata to Neptune#
Here's how you can upload the model binary to Neptune:
To upload model attributes, you can use the = operator to assign particular values and dictionaries to specific fields:
run["model/attributes/tree_count"] = model.tree_count_
run["model/attributes/feature_importances"] = dict(
zip(model.feature_names_, model.get_feature_importance())
)
run["model/attributes/probability_threshold"] = model.get_probability_threshold()
The following method will fetch the model parameters and upload them to the "model/parameters" namespace:
To stop the connection to Neptune and sync all data, call the stop() method:
You can check your results in the following namespaces, located in the All metadata tab of the run in the Neptune app:
modelnamespacetrainingnamespacedatanamespace